Yseop’s AI-based technologies generate core elements of specialist medical reports, including clinical study reports (CSR), patient narratives, and more.
Transform your organization with bespoke NLG solutions
We can work with you to build bespoke NLG applications to meet your needs, helping to streamline operations and empower your workers with tailored information and insight.
The Shared Task organized by Lancaster University and Fortia Financial Solutions is part of the Financial Narrative Processing (FNP) Workshop series.
Abstract
Financial PDF documents, though human-readable, pose a challenge to machines. Existing solutions are unable to distinguish among titles, tables, headers, and other commonly present text blocks, as well as a human eye can.
“Title Detection” was one of the two shared tasks proposed on Financial Document Structure Extraction. The objective of this shared task was to classify a given text block, that had been extracted from financial prospectuses in pdf format, as a title.
Titles are like bookmarks, which can help identify a section of a document. This can also be useful for localized processing of documents because this way one need not pass the whole document through the NLP/NLU pipeline.
Our goal was to find a way to automate information extraction on noisy data.
Rather than augment the data or the data quality, the core focus was to evaluate if we could achieve a reasonable level of accuracy without reprocessing the whole dataset.
Participants were invited to apply and submit their models and invited to present their results at the Turku University in Finland during the 22nd Nordic Conference on Computational Linguistics (NoDaLiDa’19) Conference on 30 September 2019.
Dataset
The training data consisted of 44 financial prospectuses of Luxembourg based Mutual Funds written in English. We also had access to XML version (created byPoppler tool) of each prospectus as well as a CSV file containing all the text blocks extracted from the PDFs and certain features describing each of the block, such as:
Semantic features: begins with numbering
Style features: is bold, is italic
The CSV file was constructed using heuristics and thus had noisy data. Each text block in the file was either a title or not a title. Since in any document we are bound to find more text blocks than titles, this subtask was also about classifying imbalanced data. As a consequence, any broken system that labels all the text blocks as not a title would have scored aweighted F-1 scoreof 80.12 % on the given training data.
10,000 ways that won’t work
We applied three different Machine Learning techniques to our dataset: Support Vector Machine (SVM), Bi-directional Long Short-Term Memory (Bi-LSTM) and Convolutional Neural Network (CNN)
SVM
Some of the features that we extracted from the provided training data (CSV and XML files) were:
Token count
Count of upper-case letters
Is the last character a dot(.)?
Width
Height
Font
Since the mapping of text from XML to CSV was not straightforward, the resulting feature set was noisy, and the SVM model, of course, underperformed.
Bi-LSTM
To overcome the corruption in the data, we tried to evaluate what were the useful recognition patterns we could use to train an accurate classifier. The intuition behind transformer networks is that a word is more predictable in its semantic context. The main idea of trying a Bi-LSTM network is to evaluate if contextualized word vectors are significant in detecting a title. We tried a SOTA LSTM with attention, which displayed an F1 score of 93%. This was enough to validate the hypothesis that semantic context matters in the title detection task, but not to fulfill our objective.
And the Winner is…CNN!
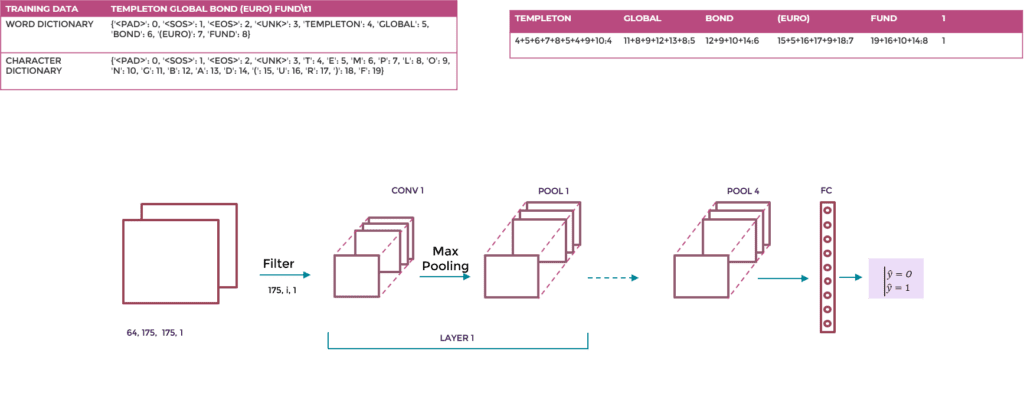
The intuition behind Y. Lecun’s paper[1] is that text is no different from the signal; thus text can be processed as pixels at the character level. The guiding principle is that the organization of characters, their sequences, is meaningful when it comes to detecting titles. With this architecture, we wanted to address both the signal detection problem and the semantic context, so we chose to add an additional convolution to the original implementation, to take into account the word embedding level and the character embedding level.
Architecture
Our CNN-based architecture ranked third among the participating teams. The input to the model is character and word embedding instead of quantized characters. This is followed by a series of four 2D convolution and pooling layers. A fully connected layer provides the probabilities of the output from the log softmax function.
The Results…
After 40 epochs of training with a learning rate of 0.0001, we obtained the best performing model of our development test dataset.
The resulting model scored 97.16 %, a percent less than the winning model.
Some of the improvement measures, such as hyper-parameter tuning, weight initialization, are discussed in our paper.
[1] X. Zhang and Y. LeCun. Character-level convolutional networks for text classification. In NIPS, 2015.
About the Yseop Innovation Lab Team
At Yseop, we endeavor to keep abreast of technology and create the perfect synergy across AI disciplines to unleash the full potential of intelligent automation.
Our Innovation Team Lab is a blended team of data scientists, linguists, NLG, NLU, and Machine Learning experts, dedicated to exploring technology developments and working on bringing the most promising, from ideation to market.
We use cookies to ensure that we give you the best experience on our website. If you continue to use this site we will assume that you are happy with it.I AgreeCookie Policy